1.1. Linguistic research perspectives
1.1.3. What is a corpus?
A corpus is a collection of texts that can be analysed using computer software. Before computers, the term corpus was sometimes used in reference to the body of work of a particular author (e.g., Shakespeare's corpus). Still, in modern linguistics, corpus almost always refers to digital collections.
A corpus is a stable and controlled dataset, meaning we know exactly what texts are in a given corpus and can repeatedly use the same corpus to answer various research questions. Corpora are typically compiled, which is another term for collected, by individual researchers or research teams for a particular purpose, but then released for the rest of the research community to use. Compiling a corpus involves various steps, from researching the background of the textual field in question, collecting and preprocessing the texts into computer-readable format, adding metadata and possibly linguistic annotations, and so on. We will discuss these issues during the course. See also Developing Linguistic Corpora: A Guide to Good Practice (ed. Martin Wynne).
Corpora may be relatively small, only comprising a few hundred thousand words, or highly massive, consisting of hundreds of billions of words. The question of how large a corpus should be, or can be, depends on the availability of texts and the research questions that are to be answered. Although it is possible to determine the minimum size of a corpus using statistical methods, corpus linguists rarely do this. In practice, the corpus size is often determined by what texts are available and how much time the research team has to prepare the data for analysis.
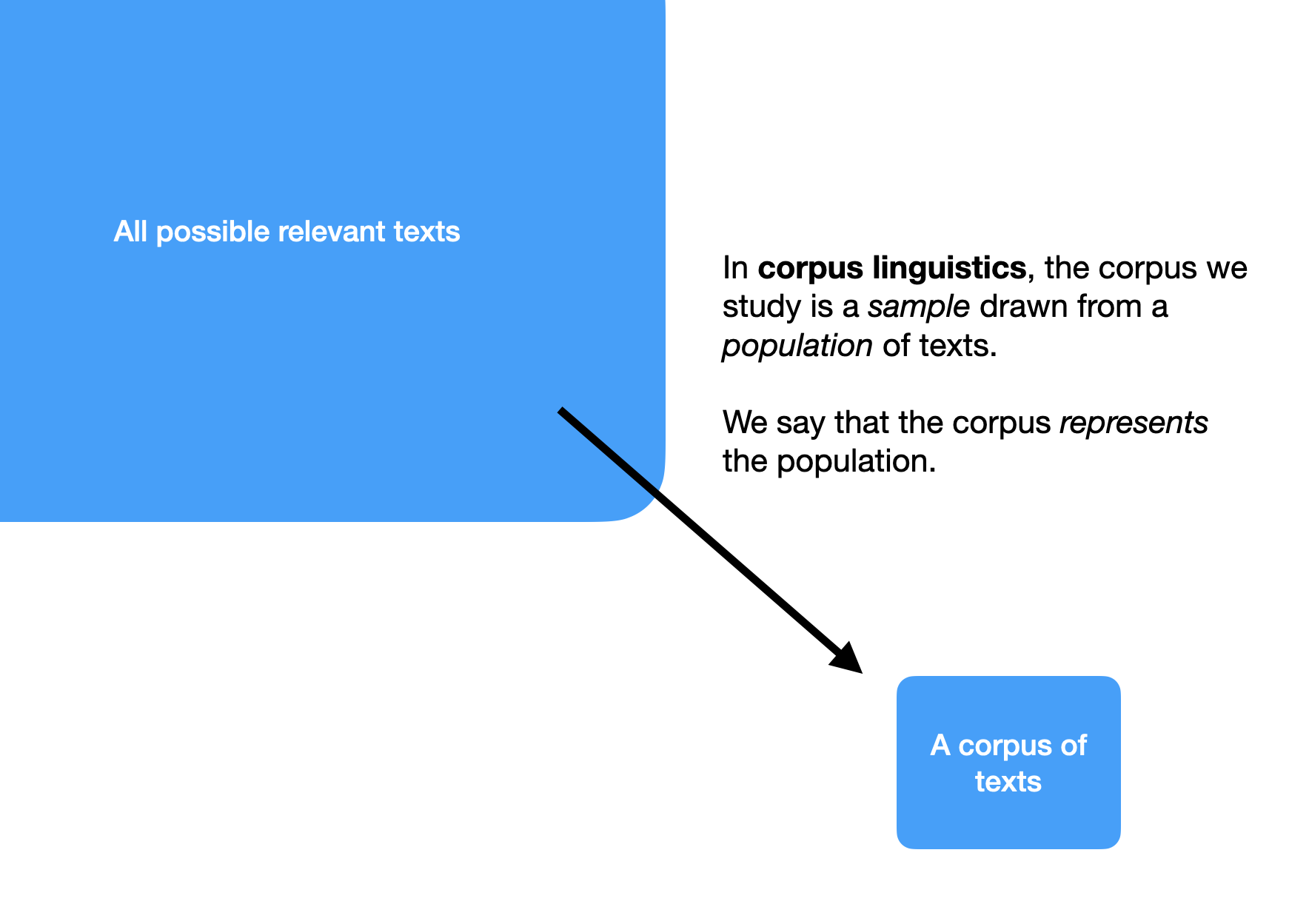
The size of a corpus is one factor that determines what questions we can meaningfully answer with it. Linguists usually consider a corpus to be a sample of language drawn from a population (see 1.3.2.), and consequently, the sample size is crucially important. The more familiar the linguistic feature we are studying, the smaller the corpus can be while still allowing us to see enough examples of the feature. On the other hand, if we are interested in how speakers use a scarce word, we may need a corpus of billions of words in size to find enough examples.
However, size isn't everything when it comes to evaluating corpora. A corpus needs to be reasonably representative of the population we are interested in studying to be useful as a resource for research. This determination of representativeness is a crucial component in corpus linguistic research. A typical corpus comprises many individual texts, each with metadata containing several descriptive variables. For example, we might know things about the authors of the texts, such as their gender, age, level of education and the region of the country they live in. We might know each text's genre or type and when it was first published. These metadata can be used when analysing findings, but they are also important when determining whether the corpus can be used to answer our research questions. For example, if our study concerns gender differences in the use of swear words, we need to ensure that the corpus contains sufficient texts from each gender of interest. If we also want to study the effects of age on swearing, we need to ensure that we have enough texts from each gender and in each age group.
There are hundreds of linguistic corpora available today. Some of them are generic corpora that model entire languages (for example, the British National Corpus or the Corpus of Contemporary American English), and others are specialised samples of specific genres, contexts of language use, or historical periods. The Corpus Resource Database (CoRD) maintained by the VARIENG research group at the University of Helsinki maintains an excellent curated list of English-language corpora that can be used as an introductory starting point to the variety of corpora that are out there.