Jelölőnyelvek és szövegmodellezés
Jelölőnyelvek vs. egyszerű szöveg
Ahogy korábban említettük, a jelölőnyelvek öröklik a korábbi nyomtatási alapú jelölési eljárások jellemzőit, miközben kiterjesztik és kiegészítik azokat az elektronikus olvasásra, elemzésre és terjesztésre. A jelölés – ahogyan korábban láttuk – kifejezhető kézzel írt karaktereken vagy szimbólumokon keresztül. Számítógépes feldolgozás esetén a jelölő vagy annotáló szókészletnek a gép számára olvasható formában és szabványosított módon kell megjelennie.
Felmerülhet a kérdés, hogy miért van szükségünk a jelölésre? Miért nem használunk egyszerű szöveget? Az egyszerű elektronikus szövegek, mint az online archívumokból (pl. Project Gutenberg) letöltött txt fájlok, általában nem tartalmaznak jelöléseket. Az emberi olvasó számára ez nem jelent problémát, amíg ismeri a nyelvet, az írási rendszert és a műfaji konvenciókat. Például az indoeurópai nyelvek olvasóinak többsége felismeri a következő műfaji típusokat anélkül, hogy olvasta volna azok tartalmát:
 |
 |
Megtanuljuk, hogyan olvassunk szöveget, hogyan különböztessük meg az egyes szavakat és azok értelmezését a nyelvi struktúrájuk összefüggésében. Még akkor is, ha a szövegek szavai között nincsenek szóközök vagy hiányoznak az írásjelek, egy emberi olvasó, aki használja ezt az írási rendszert, képes azonosítani a szavakat, a mondatokat és ezáltal felismerni azok jelentését.
Hasonlóképpen, a Cross-Hatch írás – ami a 18. században általánosan elfogadott szokás volt– egy anyagilag gazdaságosabb megoldást jelentett, mivel a levél szerzője először vízszintesen írt az oldalakra, majd miután a lap aljára ért elfordította a papírt és függőlegesen folytatta. Folyamatos írással írt ősi kéziratok és a 18. századi cross-hatch levelek bizonyítják, hogy az emberek alkalmazkodni tudnak olyan írói konvenciókhoz, amelyekben nincsenek szóközök és/vagy írásjelek. A számítógépek esetében azonban sokkal bonyolultabb az egyszerű szöveget formázni és feldolgozni, különösen akkor, ha az egyes szavakat (szófajokat), nyelvtani szerkezeteket, vagy jelentésszerkezeteket kell figyelembe venni.
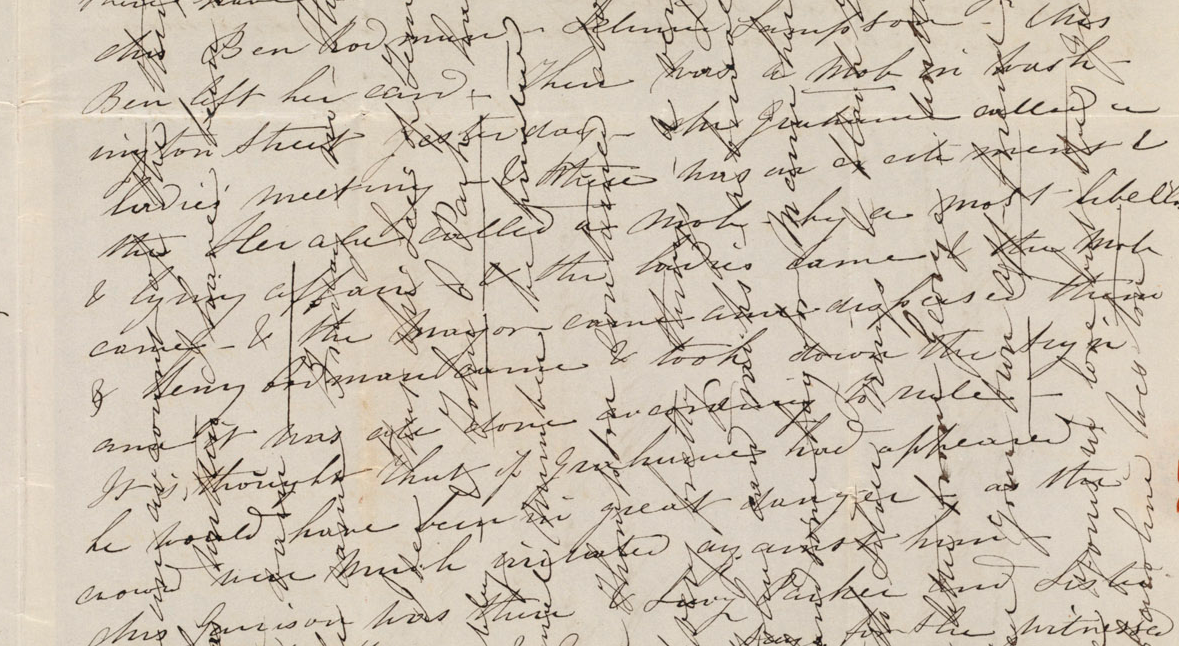 |
 |
Ezért a jelölés fontos fejlesztés, amely kibővíti az elektronikus szövegek lehetőségeit. A jelölőnyelvek az ember számára olvashatók (azaz nem kell úgy összeállítani őket, mint a programozási nyelveket), valamint leíró jellegűek, mint például a következő HTML töredék, amely két címsort jelöl, és amelyek közül az első nagyobb:
A gép által olvasható szövegközi annotációnak ezt a típusát metainformációnak, vagy metaadatnak is nevezik, mivel kiegészíti az elsődleges szöveget a további számítógépes feldolgozáshoz, ellentétben a korábbi feldolgozási módszerekkel, mint a format-17, amelyet a műcímek megjelölésére használtak.
Már az 1960-as években használták az elektronikus jelölőnyelvek korai formáit. A COCOA nevű szoftver jelölőnyelvi használata nagy befolyással bírt bölcsészeti területen. Szövegelemzésre, valamint szövegösszefüggések és szavak indexeinek létrehozására használták. Ezeket a szövegeket elő kellett készíteni és jelölésekkel kellett kiegészíteni az annotációhoz és a metaadatokhoz (további információkért lsd. Hockey 27-30). A következő példa egy drámai szövegből származó rövid részlet. A mű szerzője, címe, a felvonás és a jelenet is kódolható és feldolgozható COCOA-val:
<W SHAKESPEARE> <T HAMLET> <A 1> <S 1><C HAMLET>
Egy másik példa a jelölőnyelvekre a LaTeX nyelv, amelyet arra használnak, hogy a dokumentum jelölése révén jöjjön létre a nyomtatandó szöveg. A LaTeX-et az 1970-es évek óta fejlesztik és az egyik leggyakrabban használt nyelv a nyomdaiparban. A fenti HTML példát a következőképpen írhatjuk le LaTeX-ben:
\begin{document} \chapter{Jelölőnyelvek és szövegmodellezés} \section{Jelölőnyelvek vs. egyszerű szöveg} \end{document}
A jelölőnyelveket az egyszerű szöveg információkkal való kiegészítésére használják, amely olvasható az ember és a gép számára is. A már említett HTML és XML mind az SGML-ből (Standard Generalised Markup Language, szabványos általános jelölőnyelv) származnak. Az SGML 1986-ban vált nemzetközi szabvánnyá és egy korábbi nyelven, a GML-en (Generalised Markup Language) alapult. Az SGML nem kódolási séma, hanem egy szintaxis, vagy keretrendszer, amelyen belül kódoló címkéket lehet definiálni (Hockey 33). Az SGML, és így az XML is olyan szintaxist biztosít, amelyben ezen nyelvek használói címkéket tudnak létrehozni, ezáltal pedig olyan fogalmakat tudnak leírni, amiket fontos megragadni a szövegek és a textualitás ismeretében. Ezek a nyelvek mind ugyanazt a konvenciót követik, csúcsos zárójelet (<>) használnak az annotáció (címkék és elemek) és az elsődleges szöveg megkülönböztetésére. Ugyanezt a módszert alkalmazza a HTML és az XML is. Vegyük újra a fenti HTML példát:
Mindig van egy nyitó (pl. <h1>) és egy záró címke (pl. </h1>), amely egy címsornak az elejét és végét jelzi. Ezek a címkék a szöveg egy szemantikai funkcióját nevezik meg. A Text Encoding Initiative (TEI) kódolási szabványa egy XML nyelv, ahol ugyanezt a konvenciót és a címkék és az adatok megkülönböztetésére szolgáló zárójeleket (<>) használnak. A TEI azonban lényegesen nagyobb és gazdagabb elemkészlettel rendelkezik, hogy még több tulajdonságot tudjon megragadni a szövegtípusok széles skáláján belül, a sírfeliratoktól kezdve a digitálisan született szövegekig.
További olvasnivalóSGML Users' Group. 'A Brief History of the Development of SGML'. 1990. Online.
Hockey, Susan M. Electronic Texts in the Humanities: Principles and Practice. Oxford ; New York: Oxford University Press, 2000.